- 2003
Хранилище данных и интегрированная система
Тема хранилищ данных имеет необычайную актуальность для современных российских предприятий. Зачем предприятию нужно хранилище данных и может ли его заменить интегрированная автоматизированная система читайте в статье.
Тема Хранилищ данных имеет необычайную актуальность для современных российских предприятий. Причин этому две. Во-первых, большинство средних и крупных предприятий уже прошли стадию первичной автоматизации, то есть автоматизации бухгалтеров. Во-вторых, происходит быстрое укрупнение предприятий за счет их слияний, а также развития региональной сети. Поэтому настало время автоматизации менеджеров среднего и высшего звена. Однако не все менеджеры осознают это в должной мере. Некоторые быстро выросшие до многофилиальных структур или холдингов предприятия просто не успели столь же быстро изменить свой менталитет "маленьких" или унитарных. Другие считают, что все проблемы автоматизации крупного предприятия могут быть решены в рамках одной интегрированной автоматизированной системы. Итак, зачем нужно Хранилище данных предприятию и может ли его заменить интегрированная автоматизированная система?
Задачи Хранилища данных
В классическом представлении под целью создания Хранилище данных понимается поддержка принятия решений, другим словами обеспечение всех менеджеров предприятия полной, достоверной, согласованной и своевременной информацией из единого источника. Для реализации этой цели Хранилище данных выполняет ряд задач, которые описаны ниже.
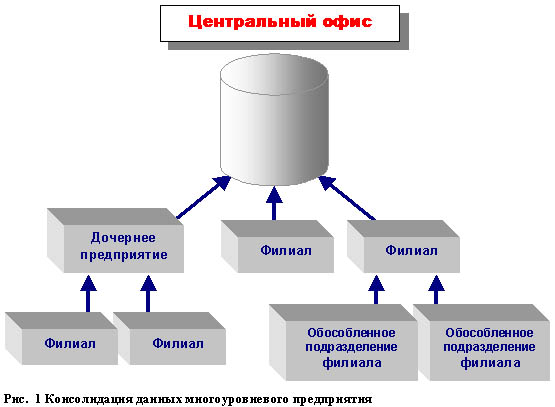
Консолидация данных
Консолидация данных - это сбор в единую базу данных из удаленных филиалов
многофилиального предприятия, или предприятий, входящих в холдинг.
Консолидированные данные необходимы центральному руководству, чтобы
осуществлять глобальное управление бизнесом, внедрять единую политику в
филиалах и осуществлять контроль над их деятельностью.
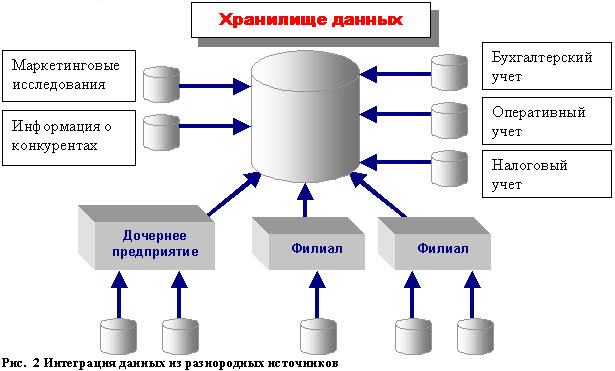
Интеграция данных
Интеграция данных - это объединение данных, которые изначально вводятся в
разные системы. Сами эти системы могут располагаться в одной локальной сети, но
иметь различные платформы и внутреннюю архитектуру. Такая ситуация практически
неизбежна во всех предприятиях занимающихся сложным бизнесом. Как правило, один
единственный поставщик не может создать систему, в которой одинаково хорошо
решены вопросы бухгалтерского учета и автоматизации производственного цикла,
управления кадрами и документооборота и так далее.
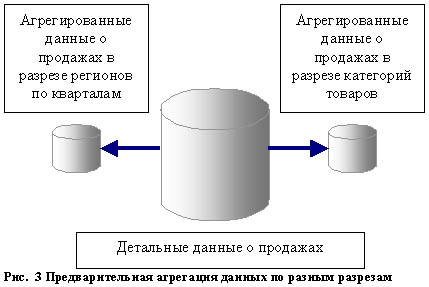
Агрегация данных
Агрегация данных - это вычисление обобщенных показателей для поддержки
стратегического или тактического управления из детальных данных. Например, все
записи о продажах двухсот тысяч наименований товаров тысяче оптовых покупателям
за каждый день года преобразуются в данные о продажах десяти категорий товаров
пяти категориям покупателей в разрезе месяцев и кварталов года и регионов. Эти
данные используются впоследствии менеджерами для принятия решений об изменениях
направлений бизнеса, расширении рынка, анализа сезонных колебаний спроса на
товары разных категорий.
Расчеты производных показателей
В управленческой практике собранные из подразделений первичные оперативные данные используются для расчета сложных финансовых и оперативных показателей, таких как прибыль на капитал, средневзвешенные цены, ликвидность, доходность клиента и т.д. Хранилище данных предоставляет формульный язык для настройки алгоритмов расчета показателей и специальные механизмы быстрого выполнения расчетов над огромными массивами первичной информации.
Предоставление данных для поддержки принятия решений (DSS)
Как уже указывалось выше, изначально концепция Хранилища данных была разработана с единственной целью - для информационной поддержки принятия решений. Поэтому предполагалось, что данные Хранилища должны быть неизменяемы. Пользовательский интерфейс обеспечивает всего две основные функции - выпуск отчетов для печати и интерактивный анализ данных. В связи с этим в качестве front-end можно применять универсальные системы выполнения запросов, анализа данных и выпуска отчетов. Эти инструменты позволяют свести к минимуму затраты на разработку отчетов, во многих случаях (для не регламентированных государством отчетов) сводя создание новых форм отчетов к настройке, выполняемой самим пользователем.
Создание комплекса управленческих приложений
Через несколько лет после эксплуатации Хранилищ обнаружилось, что наличие качественных данных в централизованной системе позволяет автоматизировать задачи управленцев, которые исторически считались слишком интеллектуальными и неформализованными для того, чтобы их можно было автоматизировать. С другой стороны управленцам требуется дополнять данные, получаемые из низовых подразделений различными признаками, не известными в этих подразделениях. Например, для создания управленческого баланса требуется ведение таблицы соответствия бухгалтерских счетов и статей управленческого баланса. Оказалось, что задачи бюджетного планирования и финансового наиболее эффективно решаются не внутри учетных систем, а на базе консолидированных данных Хранилища, хотя эти задачи и близки к OLTP-системам. В процессе бюджетного планирования в систему в многопользовательском режиме вручную вводятся плановые значения статей бюджетов, плановые документы и другие данные, что характерно для транзакционных систем, а не для систем поддержки принятия решений. Однако поскольку по определению, управленцев всегда меньше чем исполнителей, то количество пользователей таких систем также несопоставимо меньше, чем учетных, на порядки меньше и объем вводимых ими данных. Это позволяет снизить требования к скорости выполнения транзакций, поддерживая высокую скорость выполнения аналитических запросов.
Вследствие этих причин наряду с классическими информационными Хранилищами данных стали появляться управленческие информационные системы, построенные по технологии Хранилища данных или использующие данные внешних Хранилищ данных и позволяющие автоматизировать труд руководителей высшего и среднего звена. Как правило, они реализуются как совокупность разных приложений, работающих на единой платформе Хранилища данных. Эти приложения используют общие данные, но решают самые разнообразные задачи управления.Различия Хранилищ данных и учетных систем
Хранилище данных
Исходя из особых целей Хранилища данных, к нему предъявляются следующие технические требования:
База данных должны быть оптимизирована для быстрого выполнения объемных незапланированных запросов. Для этого применяется ряд специальных приемов:- Денормализация таблиц. В этом случае применяются схемы "звезда" и "снежинка" вместо многоуровневых реляционных связей. Это позволяет уменьшить количество соединений таблиц в запросах и тем самым ускорить их выполнение, но приводит к увеличению размера базы данных и снижению качества проверки ссылочной целостности.
- Создание дополнительных индексов. Это также увеличивает размеры базы данных, но ускоряет выполнение запросов.
- Специальное индексирование. Разработчики платформ Хранилищ данных создают собственные мета средства индексации, позволяющие ускорить выполнение запросов с заранее не известными условиями.
- Избыточность данных. В Хранилищах данных избегают сложных вычислений в момент выполнения запроса. Например, в учетных системах сальдовые остатки по счетам, как правило, хранятся только на дату их изменения, промежуточные же значения вычисляются в момент выполнения запроса. В Хранилищах остатки хранят на каждую дату.
- Предварительная агрегация. В хранилище заранее, в момент загрузки данных или в нерабочее время выполняется агрегация данных по времени, например, за месяц, квартал, год и по другим категориям, если заранее известно, что существенная часть запросов будет требовать не детальных, а обобщенных данных.
Наличие средств пакетной загрузки данных, с предварительной проверкой ошибок и приведением данных к стандартному виду. Для решения этой задачи применяется два принципиально разных подхода.
Первый - применение средств ETL (Extract, Transformation, Loading), специальных систем для извлечения данных из других базы данных, трансформации по описанным в этой систем правилам и загрузке в Хранилище. Эти системы позволяют описать в визуальной среде структуру источника данных, правила трансформации данных и соответствие полей и таблиц источника полям и таблицам базы данных Хранилища. На практике, не удается избежать программирования процедур извлечения данных. Второй подход - применение стандартного формата для сбора данных и разработка процедур выгрузки данных на стороне источника. Этот формат построен на описании бизнес объектов, никак не связанном со способом их физического хранения в той или иной информационной системе. Это позволяет, во-первых, собирать однородные данные из разнородных систем. Во-вторых, децентрализовать разработку процедур выгрузки данных, предоставляя решение этой задачи специалистам, обладающим знанием об исходной системе, например, ее разработчикам. В-третьих, применять для разработки процедур выгрузки наиболее подходящий для каждой системы инструмент, например, язык, встроенный в исходную систему и объектную модель этой системы. В качестве универсального формата обмена данными в настоящее время, как правило, применяется XML - универсальный, платформо-независимый язык разметки документов. Сбор данных из разнородных источников и загрузка полученных из филиалов огромных объемов данных является очень нетривиальной задачей, для решения которой необходима специализированная система, предназначенная именно для консолидации данных.Наличие пользовательских инструментов задания сложных запросов и наглядного представления их результатов. Задача поддержки принятия решений предполагает выполнение двух способов получения данных:
- Отчет - регулярно выполняемый, заранее известный запрос, или несколько запросов, результат которого представляется на экран или принтер в регламентированной форме. Как правило, скорость выполнения подобных запросов не критична и вполне допустимы минуты и даже десятки минут.
- Анализ - интерактивное выполнение запросов, когда результат одного запроса наводит пользователя на мысль о том, каким должен быть следующий запрос. Скорость выполнения подобных запросов очень критична, поскольку за одну сессию человек выполняет много запросов, и ожидание ответа ограничивает его возможности в исследованиях. Нормальным считается время отклика в режиме интерактивного анализа данных в пределах 20 секунд (тест FASMI).
Как правило, для первого способа работы с данными применяются обычные генераторы отчетов или специализированные, встроенные в Хранилище данных интерфейсы, а для второго OLAP-инструменты, которые отображают данные как в виде динамических кросс таблиц с промежуточными итогами и возможностью углубления в данные, так и в виде диаграмм и графиков.
Наличие инструментов быстрого изменения структуры базы данных для расширения номенклатуры данных и приведения информационной модели к изменяющимся требованиям бизнеса. "Все и сразу" невыполнимая задача при создании Хранилищ данных. Одной из причин неудач при создании Хранилищ данных является попытка за один этап реализовать сразу все требования организации к информационному обеспечению управления. В успешных проектах составляется поэтапный план внедрения Хранилища данных, который предполагает расширение номенклатуры данных не в момент проектирования базы, а уже в момент ее эксплуатации. Поэтому развитые платформы Хранилищ данных построены на модели метаданных, описывающих структуру Хранилища в терминах бизнеса, и оснащены инструментами дизайна, позволяющими модифицировать информационную модель системы, и автоматически генерируют структуру базы данных, процедуры ее наполнения, индексы, процедуры выполнения запросов и форматы для сбора данных и так далее.Задача изменения информационных объектов и их атрибутов и правил проверки данных возникает постоянно в связи с тем, что бизнес предприятий непрерывно развивается и изменяется. Хранилище данных должно адекватно отражать эти изменения, не требуя при этом выполнения непреодолимо сложных и трудоемких работ по модификации и сопровождению системы.
Учетная система
Очевидно, что перечисленные выше требования к Хранилищам данных не удовлетворяются учетными системами, а во многих случаях принципиально противоположны требованиям, которые предъявляются к учетным системам, в том числе к интегрированным ERP системам. Действительно, эти для решения своих ключевых функций эти системы должны:
- Быстро выполнять транзакции. Скорость выпуска отчетов для них менее критична, поэтому базы данных оптимизируются под быстрый ввод данных многими пользователями одновременно. Для этого в частности приходится уменьшать количество индексов, поскольку их обновление увеличивает время выполнения транзакций, это неизбежно приводит к уменьшению скорости выполнения запросов.
- Защищать данные от пользовательских ошибок ввода. Это требует обеспечения ссылочной целостности на уровне базы данных, а значит сложной реляционной структуры, что также существенно замедляет выполнение объемных запросов.
- Минимизировать изменения базы данных в процессе выполнения одной транзакции для ускорения ее выполнения. Это требование приводит к тому, что в базе данных часто хранятся только изменения объекта, а его текущее состояние вычисляется в момент выпуска отчетов. Например, записывается приход и расход по складу, а наличие на дату вычисляется как разница между ними. Это всегда приводит к очень медленной работе системы при выполнении произвольного многофакторного анализа за длинный исторический период.
Для консолидации данных в системах автоматизации оперативной работы предприятия применяется два подхода:
- Работа всех филиалов в единой базе данных. Очевидно, что это наиболее эффективный способ автоматизации, однако он до сих пор слишком дорог для большинства российских предприятий. Кроме того, даже наличие центральной базы данных не решает всех задач доставки информации из филиалов в центральный аппарат. Проблема связана с тем, что, как правило, не удается автоматизировать все аспекты деятельности предприятия одним программным продуктом. В крупных предприятиях всегда кроме главной системы используется множество вспомогательных систем от разных поставщиков для автоматизации различных бизнес процессов.
- Физическая репликация данных. Многие учетные системы оснащены инструментом сбора в копию системы, установленную в центре данных из копий систем, установленных в филиалах. Как правило, это выполняется на уровне репликации физических таблиц, поскольку другие способы требуют серьезных капиталовложений в реализацию, с другой стороны позволяет организации использовать разные системы в разных филиалах, что противоречит интересам поставщика. Естественно, что этот подход приводит к невозможности собрать данные, если в филиалах используются не только разные системы, но даже разные версии одной системы.
Совмещение в одной базе данных выполнения длинных аналитических запросов и выполнения транзакций десятками операторов неизбежно приводит к борьбе за вычислительные ресурсы. При этом до недопустимых величин может увеличиться время выполнения транзакций и время получения аналитических выборок.
Предметное наполнение Хранилищ данных
Таким образом, в большинстве случаев наиболее универсальным и экономичным решением для построения единого информационного пространства многофилиального предприятия является Хранилище данных. Перечислим несколько примеров приложений, наиболее эффективно реализуемых на платформе Хранилища данных:
- Управление филиалами
- Налоговая отчетность
- Анализ продаж
- Управление имуществом
- Финансовое управление и бюджетирование
- Анализ клиентской базы
- Расчеты с контрагентами
- Маркетинговый анализ
Хранилища данных и управленческие приложения на их платформе давно заняли свою нишу в структуре автоматизации западных предприятий. В России также есть предприятия, имеющие Хранилища данных собственной разработки, заказные и тиражные решения. Хранилища не заменяют интегрированные учетные системы и не могут быть заменены ими, но вместе создают целостную информационную инфраструктуру предприятия. Многолетний опыт использования этой технологии показывает ее необычайную эффективность в улучшении качества управления, и, в конечном счете, в повышении конкурентоспособности предприятия.
Автор: В.Некрасов
Источник: "RM-Magazin", 2003, №1